




যেকোন কনসেপ্ট বা সিস্টেমকে ফর্মালি ডিফাইন করতে গেলে বেশ কয়েকটা ক্রাইটেরিয়া মেইনটেইন করতে হয়, যেমন - সিস্টেম কি কাজ করে, কীভাবে করে এবং এই সিস্টেমের পেছনে মোটিভেশন কি (মানে এর কি এমন মাহাত্ম্য আছে যে এক্সিস্টিং সিস্টেমের চাইতে এই সিস্টেম ভালো কাজ করে বা করবে)। এখনকার ল্যাঙ্গুয়েজ মডেল সব নিউরাল নেটওয়ার্ক বেজড, এবং ইন্টার্নাল স্ট্রাকচার অনেক কমপ্লেক্স (যেমন - জিপিটি, টি৫, লামা২ ইত্যাদি)। এসব কমপ্লেক্স, বড় মডেল থেকে ল্যাঙ্গুয়েজ মডেলিং এর বেসিক প্রিন্সিপাল বের করতে যাওয়া বেশ কষ্টসাধ্য। আরেকটা ব্যাপার হচ্ছে, নিউরাল নেটওয়ার্ক ডিজাইনে এক্সপ্লেইনিবিলিটি খুব একটা হাই প্রায়োরিটি টপিক না । বেশিরভাগ নিউরাল নেটওয়ার্ক এমনভাবে ডিজাইন এবং ট্রেইন করা হয় যাতে তারা কোন টাস্কে সম্ভাব্য সবচে ভালো রেজাল্ট দিতে পারে। এজন্য নিউরাল নেটওয়ার্ক মেথডগুলোকে ব্ল্যাক বক্স মডেল ও বলে, কারণ এরা ডেটা থেকে কমপ্লেক্স প্যাটার্ন শিখতে যতটা এক্সপার্ট, কীভাবে কি শিখছে বা প্রেডিক্ট করছে সেটা ব্যাখ্যা করতে ততটা পারদর্শী নয়। নিউরাল নেট আদতে ক্যালকুলেটরের মতন। এরা কঠিন কাজ সহজ করে দেয়। কিন্তু কাজটা তো আদতে কোন না কোনভাবে ডিফাইন করা তাই না! তো ল্যাঙ্গুয়েজ মডেলিং এর ও কিছু বেসিক প্রিন্সিপাল আছে, যেগুলো ডিফাইন করে যে একটা ল্যাঙ্গুয়েজ মডেল কি হবে, কীভাবে কাজ করবে । আর এই প্রিন্সিপালগুলো বুঝার জন্য সবচে সহজ উপায় হচ্ছে একটা প্রি - নিউরাল নেটওয়ার্ক ল্যাঙ্গুয়েজ মডেলিং টেকনিক, N-gram ল্যাঙ্গুয়েজ মডেল কীভাবে কাজ করে সেটা দেখা। এই পোস্টে আমি স্ক্র্যাচ থেকে একটা N-gram মডেল ইমপ্লিমেন্ট করে দেখাবো যে ল্যাঙ্গুয়েজ মডেল আদতে কি করে, এবং ল্যাঙ্গুয়েজ মডেলিং এর বেসিক কি।
টার্মিনোলজি
আমার মতে টার্মিনোলজি আর জার্গন কনসেপ্টগুলো আগেভাগে ক্লিয়ার করে নিলে তোমার বাদবাকি পোস্ট পড়তে সুবিধা হবে।
টোকেন, টোকেন টাইপ, ফ্রিকুয়েন্সি
তোমার ডেটায় যে কয়টা শব্দ বা শব্দাংশ আছে (যেটাকে তুমি বেয়ার মিনিমাম ইউনিট ধরবা) সেটাকে টোকেন বলে। এখন একই টোকেন একাধিকবার আসতে পারে। ইউনিক টোকেনগুলো টোকেন টাইপ বলে। ধরো তোমার ডেটায় is ১০০ বার আছে। তাহলে তুমি বলতে পারবে যে is একটা টোকেন টাইপ। এটার ফ্রিকুয়েন্সি ১০০।
ল্যাঙ্গুয়েজ মডেলিং
যেকোন স্ট্যাটিস্টিকাল মডেলিং সিস্টেম, হোক সেটা ল্যাঙ্গুয়েজ মডেল কিংবা একটা অবজেক্ট ডিটেক্টর, এর কাজ হচ্ছে ইনপুট ডেটা থেকে প্যাটার্ন শেখা, সেই প্যাটার্নের উপর একটা প্রবাবিলিটি ডিস্ট্রিবিউশন এসাইন করা (মানে ০ থেকে ১ এর মধ্যে স্কোর এসাইন করা, যাতে প্রেডিক্ট করা যায়)। সিস্টেম ডেটার প্যাটার্ন কতো ভালোভাবে ধরতে পেরেছে তার ইন্ডিকেশন হচ্ছে সে সিস্টেমের ফাইনাল প্রবাবিলিটি ডিস্ট্রিবিউশনটা কত ভালো । এই প্যাটার্ন ধরে ডিস্ট্রিবিউশন বানানোর কাজটাকেই মডেলিং বলে ।
এই ক্রাইটেরিয়া অনুযায়ী একটা ল্যাঙ্গুয়েজ মডেল হচ্ছে এমন একটা সিস্টেম যেটা কিনা ইনপুট ডেটা কিংবা ল্যাঙ্গুয়েজ ডেটার প্রতিটা ইউনিটের জন্য প্রোবাবালিটি এসাইন করে। সহজ ভাষায় বলতে গেলে, ল্যাঙ্গুয়েজ মডেলের কাজ হচ্ছে একটা ভাষার শব্দ, বাক্য, শব্দাংশ কিংবা যেকোন অর্থবহনকারী ইউনিটের জন্য প্রোবাবিলিটি এসাইন করা। যারা LLM ইউস করে টেক্সট জেনারেট করো তারা চাইলে জিজ্ঞেস করতে পারো যে তাহলে প্রোবাবিলিটি থেকে টেক্সট জেনারেট করে ক্যামনে ? প্রোবাবিলিটি ডিস্ট্রিবিউশন থেকে স্যাম্পল করবা!
এছাড়া, ল্যাঙ্গুয়েজ মডেল মানে ভালো ল্যাঙ্গুয়েজ মডেল ভেরিফাই করতে পারে যে একটা বাক্য কতটুকু সঠিক। এখন এইটার ইউস কেস কি হতে পারে ? তোমার ল্যাঙ্গুয়েজ মডেল যদি এতটুকু জানে যে তোমার ভাষায় কি লেখা সম্ভব আর কি সম্ভব না তাহলে তুমি একটা ল্যাঙ্গুয়েজ মডেলকে ছোটখাট ডেটাবেজ হিসেবে চালিয়ে দিতে পারবা। যারা গ্রামারলি ইউস করো কিংবা অন্য কোন বানান বা গ্রামার চেকিং টুল, তারা কখনো ভেবে দেখেছো যে তোমার ভুল ধরতে এগুলো রেফারেন্স হিসেবে কি ইউস করে ?
প্রবাবিলিটি ডিস্ট্রিবিউশন আর স্যামপ্লিং
আচ্ছা এই প্রোবাবিলিটি ডিস্ট্রিবিউশন নিয়ে এত কথা বলছি, এই জিনিসটা আসলে কি ? যারা ইউনিভার্সিটিতে একটা হলেও স্ট্যাটিস্টিক্সের কোর্স করেছো তাদের জানার কথা। যারা জানো না, ধরো তোমাকে কয়েকটা ট্রায়াল করতে দেয়া হলো, যেমন কয়েন টসে কয়বার হেড কয়বার টেল আসে। সেখান থেকে তুমি হেড টেলের সম্ভাব্যতা বা প্রোবাবিলিটি বের করলা। এই মানগুলোকে একসাথে একটা র্যান্ডম ভ্যারিয়েবল বলা যায়। একটা র্যান্ডম ভ্যারিয়েবলের সবগুলো কম্পোনেন্ট যে যোগ করলে যদি যোগফল ১ হয় তাহলে তারা একটা প্রোবাবিলিটি ডিস্ট্রিবিউশন ফাংশন। ব্যস এইটুকুই। এর বেশ জানতে চাইলে তুমি স্ট্যাটিস্টিক্সের কোন বই খুলে Probability Density Function, Probability Mass Function, Discrete vs Continuous Random Variable নিয়ে পড়তে পারো।
এখন ধরো তোমার হাতে এমন কিছু প্রোবাবিলিটি ভ্যালু আছে কিংবা র্যান্ডম কিছু ভ্যালু আছে। সেগুলো যোগ করে ১ হয় না কিন্তু তুমি এদেরকে একটা প্রোবাবিলিটি ডিস্ট্রিবিউশন বানাতে চাও, অর্থাৎ র্যান্ডম ভ্যারিয়েবলকে ০ থেকে ১ এর মধ্যে স্কেল করতে চাও। তাহলে কি করবে ? এজন্য দুইটা ভালো ম্যাথম্যাটিকাল ট্রিক আছে। সিগময়েড ফাংশন আর সফটম্যাক্স ফাংশন। কিন্তু কোনটা কখন কাজে লাগে ?
সিগময়েড আর সফটম্যাক্স ফাংশন
$$\sigma (x) = \frac{1}{1 + e^{-x}}$$
সিগময়েড ইনপুটকে ০ থেকে ১ এর মধ্যে স্কেল করে নেয় ঠিকই, কিন্তু সিগময়েড সবচে ভালো কাজ করে যদি তোমার প্রোবাবিলিটি ডিস্ট্রিবিউশন বাইনারি হয়, অর্থাৎ সেখানে শুধু দুই ক্যাটাগরির প্রোবাবিলিটি ই থাকে। যেমন কয়েন টসে শুধু হেড বা টেইল এই দুই ক্যাটাগরির প্রোবাবিলিটি থাকে । তাহলে একাধিক ক্যাটাগোরির জন্য কি সফটম্যাক্স ইউস করবে ? ইয়াপ! ল্যাঙ্গুয়েজ মডেলিং এর ক্ষেত্রেও তোমাকে একাধিক প্রোয়াবাবিলিটি ক্যাটাগরি সামলাতে হবে । ধরো তুমি বাইগ্রাম মডেল বানাচ্ছো, এবং তোমার ডেটা থেকে ২ হাজারের মতন বাইগ্রাম পেয়েছো। প্রতিটার প্রোবাবিলিটি থাকবে, এদেরকে সফটম্যাক্স ফাংশন দিয়ে স্কেল করে নিলে তুমি একটা প্রোবাবিলিটি ডিস্ট্রিবিউশন পেয়ে যাবা। সফটম্যাক্সের ইকুয়েশনটা এমন-
$$s(x_{i}) = \frac{e^{x_{i}}}{\sum_{k = 1}^{n}e^{x_{k}}}$$
মানুষের ভাষায় তর্জমা করলে সফটম্যাক্সের ডেফিনিশন হচ্ছে, ধরো তোমার হাতে n সংখ্যক প্রোবাবিলিটি ভ্যালু আছে। এবং ধরো একটা করে এদের সফটম্যাক্স বের করতে চাও। তাহলে তোমাকে যেটা করতে হবে যে এই মুহুর্তে যে প্রোবাবিলিটি ভ্যালুটা কন্সিডার করছো সেটার এক্সপোনেন্ট নিতে হবে \(e^{x}\) এরপর সেটাকে সবগুলো প্রোয়াবিলিটির আলাদা আলাদা করে বের করা এক্সপোনেন্টের যোগফল দিয়ে ভাগ করতে হবে । আচ্ছা সবকিছুর যোগফল দিয়ে ভাগ দিতে হবে, এইটা প্রবাবিলিটি বের করা থেকে আলাদা হলো কীভাবে ? সফটম্যাক্সকে তুমি চাইলে নর্মালাইজড প্রোবাবিলিটিও বলতে পারে। কারণ সবগুলোকে ধরে ০ থেকে ১ এর মধ্যে নর্মালাইজ করা হচ্ছে।
(যারা নর্মালাইজেশন কি জিনিস জানো না তাদের জন্য - একগাদা সংখ্যাকে যদি একটা ডিফাইন্ড রেঞ্জের মধ্যে নিয়ে আসা হয়, যেমন ০ - ১, কিংবা ১-৫০ তাহলে সেটাকে নর্মালাইজেশন বলে)।
মাল্টিনোমিয়াল স্যাম্পলিং
ডিস্ট্রিবিউশন কি সেটা তো দেখলাই। কিন্তু জেনারেশনের কাজটা কীভাবে হয়? একটা প্রোবাবিলিটি ডিস্ট্রিবিউশন থেকে কিছু বেছে নেয়ার প্রসেসটাকে স্যামপ্লিং বলে । থিওরেটিকালি, স্যামপ্লিং এর আউটপুট নির্ভর করে তোমার প্রোবাবিলিটি ডিস্ট্রিবিউশনের উপর । টেক্সট জেনারেশনের ক্ষেত্রে তুমি চাইলে প্রতিবার ম্যাক্সিমাম প্রোবাবিলিটির শব্দ বেছে নিতে পারো। তাতে যে সমস্যা হবে সবসময় একই শব্দ জেনারেট করবে। কিংবা র্যান্ডমলি সিলেক্ট করতে পারো, তাতে সবসময় যে অর্থবহ আউটপুট সে নিশ্চয়তা নেই। মাল্টিনোমিয়াল স্যামপ্লিং করলে তুমি প্রোবাবিলিটির উপর ভিত্তি করে একেকবার একেক শব্দ পাবে। প্রসেসটা র্যান্ডম না, স্টকাস্টিক। অর্থাৎ তোমার ট্রেইন করা ডিস্ট্রিবিউশন অনুযায়ী সবচে প্রবাবল শব্দগুলোই স্যাম্পল হবে। র্যান্ডম ও না, ম্যাক্সিমাম ও না।
Pytorch কোড
import torch
# make a random_var of size 10
random_var = torch.randn(size=(10, ))
print(random_var)
tensor([-1.0539, 1.0529, 1.3023, -0.4860, 0.6925, -0.6998, 0.3889, 0.5154, 0.3058, -1.3593])
# softmax
prob_dist = random_var.softmax(dim=-1)
print(prob_dist)
# verify that prob_dist sums to 1
print(prob_dist.sum())
tensor([0.0236, 0.1941, 0.2490, 0.0417, 0.1353, 0.0336, 0.0999, 0.1134, 0.0919, 0.0174])
tensor(1.)
এখন ধরো, প্রোবাবিলিটি ডিস্ট্রিউবশন থেকে প্রতিবারে ৩ টা করে ভ্যালু স্যাম্পল করবো।
gen_out = torch.multinomial(prob_dist, 3)
print(gen_out)
tensor([7, 3, 5])
কিন্তু ৭, ৩ কিংবা ৫ তো র্যান্ডম ভ্যারিয়েবলে ছিলো না! torch.multinomial ইনডেক্স রিটার্ন করে। তুমি চাইলে এখন এই ইনডেক্সগুলো ইউস করে কোন কোন র্যান্ডম ভ্যালু পিক করা হয়েছে সেটা বের করতে পারবে (একটু পরেই ল্যাঙ্গুয়েজ মডেলের ইমপ্লিমেন্টেশনে দেখাবো, চিন্তার কিছু নাই) ।
যারা পাইটর্চ আগে ইউস করো নাই তাদের কাছে এগুলো কঠিন লাগতে পারে। এই আর্টিকেলে আমি এমন আহামরি কোন পাইটর্চ কোড ইউস করবো না। আর পাইটর্চ নিয়ে লিখতে গেলে আস্ত একটা বই লেখা যাবে। এরচে বরং আমি আলাদা একটা পোস্টে বেসিক জিনিসগুলো নিয়ে লিখবো । আপাতত জাস্ট ফলো করে যাও।
N-gram কি জিনিস ?
প্রি নিউরাল নেট যুগে, এনএলপিতে মানে স্ট্যাটিস্টিকাল এনএলপিতে N-gram ই ল্যাঙ্গুয়েজ মডেলিং এর সবচে পপুলার টেকনিক ছিলো । NLP তে বাক্যকে সিকোয়েন্স ধরা হয়। N-gram হচ্ছে এমন একটা সিকোয়েন্স থেকে পাশাপাশি থাকা N সংখ্যক শব্দ নিয়ে বানানো একটা সাবসিকোয়েন্স। একটা উদাহরণ দেই।
The secret identity of Batman is Bruce Wayne.
এখান থেকে প্রতিটা শব্দ আলাদা করে নিলে (মানে একটা শব্দই একটা সাবসিকোয়েন্স) এমন দাঁড়াবে -
The
secret
identity
of
Batman
is
Bruce
Wayne
এই কালেকশনটায় N = 1, এখানে সব 1-gram বা ইউনিগ্রাম। তাহলে ইউনিগ্রামের কনসেপ্ট টা কি দাঁড়ালো ? ইউনিগ্রামে প্রতিটা শব্দ ইনডিপেন্ডেন্ট অর্থাৎ আশেপাশে কি শব্দ আছে সেটার কোন ইফেক্ট এদের উপর নাই। কিন্তু, একটা অর্থবহ বাক্যে তো কখনো শব্দগুলো এভাবে একলা থাকে না। বরং তাদের মধ্যে ডিপেন্ডেন্সি থাকে। একারণে ডেটা স্ট্যাটিস্টিক জানা বাদে ইউনিগ্রামের খুব একটা কার্যকারিতা নেই। তবে N এর মান যদি বাড়াই ?
N = 2 হলে সেটাকে বলে বাইগ্রাম। আমি পাশাপাশি থাকা দুইটা শব্দ নিবো ।
The secret
secret identity
identity of
of Batman
Batman is
is Bruce
Bruce Wayne
N = 3, ট্রাইগ্রাম ।
The secret identity
secret identity of
identity of batman
of Batman is
Batman is Bruce
is Bruce Wayne
প্রশ্ন করতে পারো, এদের পাশাপাশিই কেন থাকতে হবে? খেয়াল করে থাকলে এতক্ষণে তোমার ধরে ফেলার কথা যে N-gram এ শব্দের সংখ্যা যত বাড়ছে ততো তাদের একটা অর্থবহ বাক্য গঠনের টেন্ডেন্সি বা প্রবণতা বাড়ছে। এবং মানুষ যখন বাক্য গঠন করে তখন তারা এলোপাতাড়ি একগাদা শব্দ ছুঁড়ে দেয় না। তাদের মধ্যে একটা কানেকশন থাকে। এই যে পাশাপাশি কতগুলো শব্দ নিয়ে একটা প্রায় অর্থবহ সাবসিকোয়েন্স বানালাম, এই জিনিসটার আরেকটা নাম আছে । এটাকে কনটেক্সট বলে। কনটেক্সট যত বড় হবে তোমার ল্যাঙ্গুয়েজ মডেল তত বেশি প্যাটার্ন একবারে ধরতে পারবে । এখানে বলে রাখা ভালো, আধুনিক ল্যাঙ্গুয়েজ মডেলিং এ কন্টেক্সট সাইজ একটা বেশ বড় প্রবলেম, কন্টেক্সট যত বড় হয় , মডেল ট্রেইন এবং রান করতে তত বেশি রিসোর্সের দরকার হয়। কীভাবে বড় কন্টেক্সটের জন্য ল্যাঙ্গুয়েজ মডেলিং অপ্টিমাইজ করা যায় সেটা একটা বেশ একটিভ রিসার্চ ফিল্ড। এসব বড় মডেলের তুলনায় N-gram নেয়াহেত বাচ্চা। কিন্তু N এর সাইজ বাড়াতে থাকলে এখানেও তোমাকে রিসোর্সের সংকটে পড়তে হবে। কীভাবে? একটু পড়েই সেটা দেখবা। তার আগে ল্যাঙ্গুয়েজ মডেলিং রিলেটেড আরো কিছু কনসেপ্ট ক্লিয়ার করে নেই।
বিঃদ্রঃ পাশাপাশি শব্দ যখন নিচ্ছো তখন সেটা শুধু এক ডিরেকশনেই যাবে। মানে ডানে থেকে বামে, যেভাবে লোকে লেখা পড়ে সেভাবে। (যদি ভাষার ডিরেকশন অন্য রকম হয়? যেমন আরবিতে ডানে থেকে বামে যায়, ওয়েল, তখন ডিরেকশন বদলাবা)।
রিক্যাপ
তাহলে ল্যাঙ্গুয়েজ মডেলিং আরেকবার রিক্যাপ দেই।
১ - ডেটা থেকে প্রোবাবিলিটি ডিস্ট্রিবিউশন বানাতে হবে। ২ - সেটা থেকে জেনারেট করা যাবে।
এক্সট্রা - N-gram এর ক্ষেত্রে N এর মান ঠিক করতে হবে। আমি ইউনিগ্রাম, বাইগ্রাম, ট্রাইগ্রাম এই ৩ তার ইমপ্লমেন্টেশন দেখাবো । এর বেশিও ছিলো এক সময়ে, যেমন গুগল ট্রান্সলেট আদি আমলে 5-gram বা পেন্টাগ্রাম ইউস করতো। কিন্তু বেসিক কনসেপ্ট বুঝার জন্য আমাদের অতদুর যাবার দরকার নেই। আর আমাদের গুগলের মতন এত রিসোর্স ও নেই।
এ পর্যায়ে এসে একটু ব্রেক নাও, ঘুরে ফিরে আসো কারণ সামনে আরো অনেক কাবজাব বাকি আছে।
N-gram ইমপ্লিমেন্টেশন
ডেটাসেট / করপাস
corpus = """
Batman is an American superhero.
The secret identity of Batman is Bruce Wayne, an American billionaire from Gotham City.
The Joker is a supervillain that embodies the ideas of anarchy and chaos.
The Joker and Batman fight the battle for Gotham’s soul.
"""
এটাকে ঠিক করপাস বলা যায় কিনা জানি না। আমার মাস্টার্সের প্রথম এসাইনমেন্ট এই ছোট্ট প্যারাগ্রাফটা ডেটাসেট হিসাবে ছিলো। ঠিক ল্যাঙ্গুয়েজ মডেলিং এর জন্য না, কিন্তু এর একটা ইন্টারেস্টিং অ্যাপ্লিকেশন আছে যেটা শেষের দিকে দেখাবো । এখন, এখান থেকে কিছু জিনিস আমাদের বাদ দিতে হবে। যেমন, এখানে নিউলাইন ক্যারেক্টার আছে, এরপর এদেরকে জাস্ট মডেল সিম্পল রাখার স্বার্থে লোয়ারকেস করতে হবে ।
# lowercase
all_text = corpus.lower()
# remove . and ,
all_text = all_text.replace(".", "")
all_text = all_text.replace(",", "")
# split at new lines
sentences = all_text.split('\n')
# remove empty lines
sentences = [sentence.strip() for sentence in sentences if sentence != ""]
print(sentences)
['batman is an american superhero.',
'the secret identity of batman is bruce wayne, an american billionaire from gotham city.',
'the joker is a supervillain that embodies the ideas of anarchy and chaos.',
'the joker and batman fight the battle for gotham’s soul.']
টোকেনাইজেশন এবং ভোকাবুলারি
এভাবে আস্ত সেন্টেন্স নিয়ে তো আর N-gram বানানো যাবে না, আমাদের টোকেন বানাতে হবে। টোকেনাইজেশন ও NLP তে একটা বেশ ইন্টারেস্টিং টপিক, বিশেষ করে প্রি নিউরাল নেট যুগে টোকেনাইজেশন লোকের জন্য বেশ মাথাব্যাথার কারণ ছিলো। একটা বাক্য বা স্ট্রিং কে ছোট ছোট ভাগে ভাগ করবো ঠিক আছে কিন্তু স্প্লিটিং পয়েন্ট টা হবে কই ? হোয়াইটস্পেস ? যেসব ভাষায় হোয়াইট স্পেস নাই (যেমন চাইনিজ) তারা কি করবে ? এক ভাষার টোকেনাইজার কি আরেক ভাষায় কাজ করবে ? ইত্যাদি। আমাদের এত ঝামেলা নেই। করপাস সিম্পল। টোকেনাইজেশন ও সিম্পল।
def tokenize_sentence(sentence: str) -> list:
# split on whitespace
s = sentence.split(" ")
return s
tokens = []
for sentence in sentences:
toks = tokenize_sentence(sentence)
tokens.extend(toks)
print(f"Token types : {len(set(tokens))}")
print(f"Token count : {len(tokens)}")
Token types : 29
Token count : 42
আমাদের এখানে ইউনিক টোকেন আছে ২৯ তা। মোট টোকেন ৪২ টা। তাহলে আমাদের ভোকাবুলারি, মানে ইউনিক টোকেনের কালেকশনের সাইজ হচ্ছে ২৯।
শব্দ থেকে ইনডেক্স ম্যাপিং
স্ট্যাটিস্টিক্স শব্দ বুঝে না, ভাষাও বুঝে না । তাকে সংখ্যা না দিলে সে কাজ করতে পারবে না। কথা হচ্ছে আমার ডেটায় সব হচ্ছে শব্দ। সংখ্যা বানাবো ক্যামনে ? NLP তে সবচে কমন সমাধান হচ্ছে ভোকাবুলারির প্রতিটা শব্দের সাথে একটা করে ইনডেক্স এসাইন করে একটা ডিকশনারি বানানো । ইনডেক্স কেন ? পাইটর্চের multinomial ফাংশন ইনডেক্স রিটার্ন করে, তাই এই ডিকশনারি থেকে ইনডেক্স ধরে শব্দ বের করা যাবে।
ইউনিগ্রাম LM, (N = 1)
ইউনিগ্রামের কনসেপ্ট টা যেন কি ছিলো ? প্রতিটা শব্দ ইনডিপেন্ডেন্ট। তো এদের ইন্ডিভিউজুয়াল প্রোবাবিলিটি বের করতে হবে। এবং সেজন্য আগে এদের ফ্রিকুয়েন্সি বের করা লাগবে। আর যেহেতু আমাদের সবচে ছোট ইউনিট গোটা শব্দগুলোই, জাস্ট টোকেন গুলোই আমাদের ইউনিগ্রামের কাজ করে দিবে ।
from collections import Counter
vocabulary = Counter(tokens)
vocabulary_size = len(vocabulary)
print(f"Vocabulary size: {vocabulary_size}")
Vocabulary size: 29
# word to index mapping
# and the reverse as well
word_to_idx = {w: i for i, (w, _) in enumerate(vocabulary.items())}
idx_to_word = {i: w for i, (w, _) in enumerate(vocabulary.items())}
# unigram counts
# basically word counts
unigram_counts = torch.zeros(size=(vocabulary_size, ), dtype=torch.float)
for idx, word in idx_to_word.items():
unigram_counts[idx] = vocabulary[word]
ফ্রিকুয়েন্সি কাউন্ট পেয়ে গেছি এবার প্রোবাবিলিটি বের করার পালা।
আচ্ছা নর্মাল পাইথন লিস্টের বদলে পাইটর্চ টেনসর ইউস করলে কি এমন সুবিধা পাওয়া যায় ? এক - টেনসর লিস্টের চাইতে ফাস্ট। দুই - চাইলে জিপিউতে পাঠানো যায়। (যদি এখানে জিপিউ এর দরকার নাই)। তিন - লিস্টে সরাসরি সব ম্যাথ অপারেশন এপ্লাই করা যায় না।
# get unigram probabilities
unigram_probabilities = unigram_counts / unigram_counts.sum()
তাহলে আর বাকি রইলো কি ? প্রোবাবিলিটি পেয়ে গেছি, এখন শুধু ডিস্ট্রিবিউশন বানিয়ে জেনারেট করতে হবে!
def generate_unigram(probabilities: torch.Tensor, idx_to_word: dict, num_tokens: int):
probas_softmax = probabilities.softmax(dim=-1)
idxs = torch.multinomial(probas_softmax, num_tokens, replacement=False)
generated = [idx_to_word[i.item()] for i in idxs]
# join all into a string
generated = " ".join(generated)
return generated
# call
print(generate_unigram(unigram_probabilities, idx_to_word, 5))
wayne, gotham’s city. a soul.
আচ্ছা এক কাজ করি নাহয়। ফাংশনটা বেশ কয়েকবার কল করে দেখি সে কি জেনারেট করে।
# generate 10 times
for _ in range(10):
print(generate_unigram(unigram_probabilities, idx_to_word, 5))
anarchy for that city. american
chaos. joker identity and from
is joker gotham secret batman
superhero. secret wayne, gotham’s battle
gotham the soul. anarchy ideas
ideas identity battle anarchy for
chaos. ideas superhero. for an
chaos. batman for wayne, battle
joker supervillain gotham the billionaire
gotham’s joker bruce supervillain batman
আউটপুট এমন কেন ?
জেনারেশনের কোয়ালিটি খুবই অদ্ভুত। মনে হচ্ছে যেন একগাদা শব্দ জাস্ট বসিয়ে দিয়েছে। এর পেছনে কারণ হচ্ছে ইউনিগ্রামে সব যেহেতু ইনডিপেন্ডেন্ট, তাই তারা পরোয়া করে না আশেপাশে কি আছে। অর্থাৎ কন্টেক্সট নেই বললেই চলে। কন্টেক্সট খুব ইম্পর্টেন্ট। দেখা যাক বাইগ্রামে অবস্থার কোন উন্নতি হয় কিনা ।
বাইগ্রাম LM, (N = 2)
# create bigrams from all_tokens
bigrams = [(all_tokens[i], all_tokens[i+1]) for i in range(len(all_tokens)-1)]
bigram_counts = Counter(bigrams)
এ পর্যায়ে এসে একটু থামা দরকার। কারণ বাইগ্রাম ইউনিগ্রামের মতন এত সিম্পল না । এখানে ইউনিগুলোর মধ্যে একটা পাশাপাশি থাকার টেন্ডেন্সি বা ডিপেন্ডেন্সি আছে। বাইগ্রাম ল্যাঙ্গুয়েজ মডেলের ফর্মাল ডেফিনিশন দিয়ে শুরু করি (আসলে এই ডেফিনিশন ইউনিগ্রাম বাদে সব n-gram এর জন্যই প্রযোজ্য)। বাইগ্রাম ল্যাঙ্গুয়েজ মডেলের ডেফিনিশন হচ্ছে যে যে প্রতিটা শব্দ তার আগে কোন শব্দ আছে সেটার উপর নির্ভরশীল। ধরো তোমার কর্পাসে ভাত শব্দের সাথে ডাল, খাই, রাঁধি এই তিনটা শব্দ সবচে বেশিবার আছে। তাহলে তুমি যখন টেক্সট জেনারেট করতে যাবে কিংবা প্রোবাবিলিটি এসাইন করতে যাবে, তখন তোমাকে তাবৎ ভোকাবুলারির সব শব্দ থেকে স্যাম্পল না করে (যেটা ইউনিগ্রাম করে), শুধু ভাত এর সাথে এক কন্টেক্সট এ ছিলো এমন শব্দগুলো স্যাম্পল করলেই চলবে। এতে কি এমন বদলাচ্ছে ? ইউনিগ্রামে কখনো তুমি একটা শব্দের সাথে কন্টেক্সট শেয়ার করে এমন শব্দ স্যাম্পল করার গ্যারান্টি দিতে পারবা না। এ কারণে জেনারেশনের কোয়ালিটি ও তথৈবচ হয়। বাইগ্রামের কন্টেক্সট ছোট হলেও (সাথের মাত্র একটা শব্দ) সে তোমাকে কিছু বাড়তি ইনফরমেশন দিচ্ছে। জেনে রাখা ভালো, দুইটা শব্দের এভাবে পাশাপাশি কন্টেক্সট শেয়ার করাটাকে কোলোকেশন ডিসকভারি বলে। আমি মেলাদিন আগে একটা পোস্ট লিখেছিলাম এই নিয়ে। পড়তে পারো।
এখন বাইগ্রাম প্রোবাবিলিটি বের করবো। কিন্তু বাইগ্রামে যেহেতু দুইটা শব্দের মাঝে ডিপেন্ডেন্সি আছে, তার মানে এদের প্রোবাবিলিটি কন্ডিশনাল। ধরো একটা সিকোয়েন্সে দুইটা শব্দ আছে, \(w_{i - 1}\) আর \(w_i\) , তাহলে তাদের বাইগ্রাম হবার প্রোবাবিলিটি হচ্ছে
$$P(w_{i} \mid w_{i - 1}) = \frac{C(w_{i} \mid w_{i -1})}{C(w_{i - 1})}$$
অর্থাৎ দুইটা শব্দের বাইগ্রাম প্রবাবিলিটি হচ্ছে তাদের বাইগ্রাম কাউন্ট / বাইগ্রামের প্রথম ইলিমেন্টের ইউনিগ্রাম কাউন্ট । কেন প্রথম ইলিমেন্ট ? এর কারণ হচ্ছে বাইগ্রামের প্রতিটা শব্দ তার আগেরটার উপর নির্ভরশীল এবং কন্ডিশনাল প্রোবাবিলিটির রুল অনুযায়ী টোটাল কাউন্ট হিসেবে ইন্ডিপেন্ডেট ভেরিয়েবলের কাউন্টটা আমরা নিবো। এর মানে কি ? মানে হচ্ছে যে নর্মাল প্রোবাবিলিটি নিলে যেখানে নাকি পুরো ভোকাবুলারির সাইজ দিয়ে ভাগ দিতাম সেখানে এখন আগের শব্দটার মোট যে কয়টা বাইগ্রাম আছে সে কয়টাকে টোটাল ধরবো । এর কারণে আরেকটা ইফেক্ট আসবে। বাইগ্রামে শব্দগুলো কন্টেক্সট শেয়ার করে। তাই জেনারেশনের সময়ে আমাকে শুধু পূর্ববর্তী শব্দটার সাথে রিলেটেড যে কয়টা শব্দ আছে (বাইগ্রামের সেকেন্ড ইলিমেন্ট) সেগুলোর প্রোবাবিলিটি ডিস্ট্রিবিউশন নিলেই চলবে। এটাকে কোন সিকুয়েন্সের মারকভ প্রোপার্টি বলে আর এ ধরণের প্রোপার্টি ফলো করা সিকুয়েন্সকে বলা হয় মার্কভ চেইন । মার্কভ প্রোপার্টি অনুসারে, বর্তমানে থাকা প্রতিটা চেইন ইলিমেন্ট তার ইমিডিয়েট অতীত ইলিমেন্টের উপর নির্ভরশীল, এবং অতীত ইলিমেন্ট ফিউচার ইলিমেন্টকে ইনফ্লুয়েন্স করতে পারে না। মার্কভ চেইনের একটা ফিলোসফিকাল ইমপ্লিকেশন আছে - তুমি বর্তমানকে অগ্রাহ্য করে অতীত নিয়ে পরে থাকলে তোমার ভবিষ্যৎ আন্ধার। এহেম।
আচ্ছা বাইগ্রাম প্রোবাবিলিটিগুলো কি কোনভাবে প্লট করা যায় ? ইউনিগ্রামে প্রোবাবিলিটিগুলোকে একটা 1-Dimension এর টেনসর এ রাখা যায়। বাইগ্রামে যেহেতু পাশাপাশি দুইটা শব্দ, তাই আমার 2-Dimension এর টেনসর লাগবে। মানে একটা ম্যাট্রিক্স। আরো ভালোভাবে বললে একটা গ্রিড বা টেবিল। টেবিল প্লট করা যায়।
# bigram probabilities
bigram_probabilities = torch.zeros(size=(vocabulary_size, vocabulary_size), dtype=torch.float)
for bigram, count in bigram_counts.items():
word1, word2 = bigram
# idx of word1 and word2
idx1, idx2 = word_to_idx[word1], word_to_idx[word2]
bigram_probabilities[idx1][idx2] = count / unigram_counts[idx1]
# plot bigram probabilities as a grid
%matplotlib inline
%config InlineBackend.figure_format = "retina"
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
plt.figure(figsize=(25, 25))
ax = sns.heatmap(bigram_probabilities, linewidth=0.5, cmap="magma")
ax.set_xticklabels(idx_to_word.values())
ax.set_yticklabels(idx_to_word.values())
plt.title("Bigram Probabilities")
plt.show()
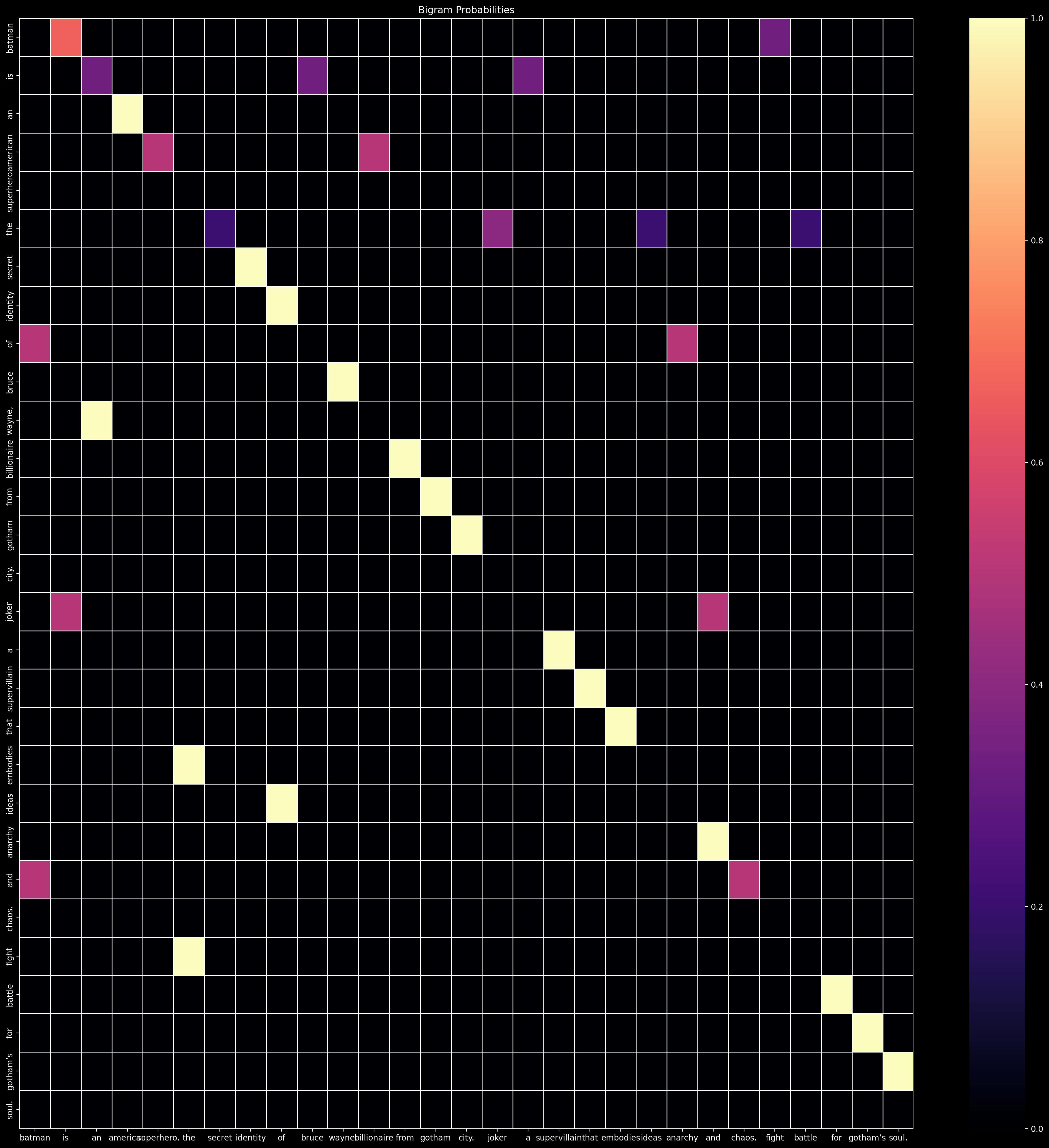
বাইগ্রামের জন্য জেনারেশন ফাংশনটা একটু বদলাবো। এবার একটা ইনিশিয়াল টোকেন দিবো, যেটাকে বেসিস ধরে পরবর্তী টোকেনগুলো জেনারেট হবে।
def generate_from_bigram(init_token: str, bigram_probabilities: torch.Tensor, num_tokens: int, idx_to_word: dict) -> str:
idx = word_to_idx[init_token]
generated_tokens = []
for _ in range(num_tokens):
# proba dist for word at idx
proba = bigram_probabilities[int(idx)].softmax(dim=-1)
idx = torch.multinomial(proba, num_samples=1).item()
generated_tokens.append(idx_to_word[idx])
return init_token + " " + " ".join(generated_tokens).strip()
print(generate_from_bigram("batman", bigram_probabilities, 5, idx_to_word))
batman supervillain wayne, ideas fight city.
ব্যাটম্যান যদিও সুপারভিলেন না, তাও জেনারেশন ইউনিগ্রামের চাইতে কিছুটা ভালো আছে।
for _ in range(10):
print(generate_from_bigram("batman", bigram_probabilities, 5, idx_to_word))
batman is embodies batman gotham’s chaos.
batman soul. city. chaos. embodies supervillain
batman gotham secret fight identity of
batman chaos. gotham of of soul.
batman gotham’s joker city. an battle
batman the supervillain fight that an
batman supervillain that superhero. that soul.
batman of supervillain american wayne, city.
batman of supervillain city. from bruce
batman fight from the that gotham
ট্রাইগ্রাম LM, (N = 3)
আশা করি ট্রাইগ্রাম কীভাবে কাজ করে এতক্ষণে ধরে ফেলেছো। আর না পারলে ………… বাইগ্রামে প্রতিটা শব্দ টার আগের একটা শব্দের উপর নির্ভরশীল ছিলো, এখন আগের ২ টা শব্দের উপর নির্ভরশীল হবে । মানে \(N - 1\) শব্দের উপর নির্ভরশীল হবে । এখানে ৩ডি টেনসর লাগবে, তাই আর প্লট করলাম না। জেনারেশন ফাংশনে একটার বদলে দুইটা ইনিশিয়াল শব্দ দিলাম।
# create trigrams from all_tokens
trigrams = [(tokens[i], tokens[i+1], tokens[i+2])
for i in range(len(tokens) - 2)]
trigram_counts = Counter(trigrams)
trigram_probabilities = torch.zeros(size=(vocabulary_size, vocabulary_size, vocabulary_size), dtype=torch.float)
for trigram, count in trigram_counts.items():
word1, word2, word3 = trigram
idx1, idx2, idx3 = word_to_idx[word1], word_to_idx[word2], word_to_idx[word3]
trigram_probabilities[idx1, idx2, idx3] = count / (bigram_counts.get((word1, word2), 1))
def generate_from_trigram(init_bigram: tuple, trigram_probabilities: torch.Tensor, num_tokens: int, idx_to_word: dict) -> str:
idx1, idx2 = word_to_idx[init_bigram[0]], word_to_idx[init_bigram[1]]
generated_tokens = [*init_bigram]
for _ in range(num_tokens):
proba = trigram_probabilities[idx1, idx2].softmax(dim=-1)
idx = torch.multinomial(proba, num_samples=1).item()
generated_tokens.append(idx_to_word[idx])
# update idx1, 2 to new tokens, so they pick up the context
idx1 = word_to_idx[generated_tokens[-2]]
idx2 = word_to_idx[generated_tokens[-1]]
return " ".join(generated_tokens).strip()
# call
print(generate_from_trigram(("batman", "is"),
trigram_probabilities + 1, 5, idx_to_word))
'batman is gotham wayne, ideas joker city.'
# generate 10 times
for _ in range(10):
print(generate_from_trigram(("batman", "is"),
trigram_probabilities + 1, 5, idx_to_word))
batman is joker embodies superhero. ideas the
batman is soul. supervillain joker anarchy supervillain
batman is identity is that identity batman
batman is gotham’s battle secret american secret
batman is embodies gotham’s city. fight identity
batman is gotham’s for is superhero. embodies
batman is identity batman and ideas ideas
batman is chaos. anarchy that secret anarchy
batman is that city. gotham’s and the
batman is a joker for gotham american
বড় কন্টেক্সট আর মেমরি কমপ্লেক্সিটি
আগের চাইতে জেনারেশন অনেক ভালো হয়েছে। কেন ? কারণ কন্টেক্সটের সাইজ বেড়েছে। কন্টেক্সট বড় হলে ল্যাঙ্গুয়েজ মডেলের জেনারেশন ক্যাপাবিলিটি ভালো হয়। কিন্তু n-gram এ কন্টেক্সট বড় করতে গেলে একটা ঝামেলা আছে। প্রোবাবিলিটি টেনসরগুলোর সাইজ দেখো। ইউনিগ্রামে ছিলো vocabulary_size, বাইগ্রামে vocabulary_size, vocabulary_size , ট্রাইগ্রামে vocabulary_size, vocabulary_size, vocabulary_size এভাবে বাড়ছে। N এর মানের সাথে প্রোবাবিলিটি স্টোর করার মেমরি কমপ্লেক্সিটি \(O(V^N)\) সাইজে বেড়েছে ( \(V\) হচ্ছে ভোকাবুলারি সাইজ)। আমাদের ভোকাবুলারি ছোট। ২৯ টা টোকেন সবে। চিন্তা করো একটা প্র্যাকটিকাল সিস্টেমে যখন কয়েক হাজার থেকে কয়েক লাখ সাইজের ভোকাবুলারি দিবে, তখন কেমন মেমরি লাগবে। এবং জেনারেশন কোয়ালিটি দেখে বুঝতেই পারছো যে ট্রাইগ্রাম ও খুব একটা সুবিধার না।
সেন্টেন্স প্রোবাবিলিটি
ধরো তোমার হাতে একটা মডেল আছে। কেউ তোমাকে একটা সেন্টেন্স দিলো আর বললো, এই সেন্টেন্সটা কি এই ল্যাঙ্গুয়েজ মডেল থেকে জেনারেট করা সম্ভব? তার মানে তোমাকে এর প্রোবাবিলিটি বের করতে হবে । কীভাবে করবা ? এই পার্টটার জন্য আমি পাঠন কোড দিলাম না। খুব সহজ, নিজেই করতে পারবা। ধরো তোমার মডেলটা বাইগ্রাম। আর সেন্টেন্সটা হচ্ছে -
the joker is a supervillain
তাহলে,
$$P(\textit{the joker is a supervillain}) = P(\text{supervillain} \mid \text{a}) \times P(\text{a} \mid \text{is}) \times P(\text{is} \mid \text{joker}) \times P(\text{joker} \mid \text{the})$$
তোমার কাছে প্রোবাবিলিটি হিসাব করাই আছে। জাস্ট গুণ করতে হবে। কিন্তু তোমাকে দেয়া সেন্টেন্সে যদি এমন শব্দ থাকে যেটা ভোকাবুলারিতে নেই। তাহলে কি করবে ? কাউন্ট ০, প্রোবাবিলিটি ও ০। গুণ করার কারণে পুরো সেন্টেন্সের প্রোবাবিলিটিই ০ হবে ।
স্মুথিং
এ জাতীয় আউট অফ ভোকাবুলারি কেসে স্মুথিং করা লাগে। স্মুথিং এ যেটা করা হয় যে ওভারল n-gram কাউন্টগুলোকে এমনভাবে এডজাস্ট করা হয় যাতে কোনটাই ০ না হয়। যেমন টিপিকালি, ভোকাবুলারিতে একটা স্পেশাল টোকেন অ্যাড করা হয়, যেটাকে আউট অফ ভোকাবুলারি টোকেন বা OOV টোকেন বলে। সেটার কাউন্ট বাই ডিফল্ট ১ করে দেয়া হয়, কিংবা ০ হিসাবে ইনিশিয়ালাইজ করে এরপর স্মুথিং করা হয়। স্মুথিং এর বেশ কিছু টেকনিক আছে। সবচে সহজ হচ্ছে অ্যাড ১ স্মুথিং। সব কাউন্টের মান ১ করে বাড়িয়ে দিবা, ব্যস শেষ। (খেয়াল করলে দেখবা যে আমি অলরেডি ট্রাইগ্রামের প্রোবাবিলিটিতে ১ যোগ করে দিয়েছি, বাইগ্রামে দিলে কি হবে সেটা নিজে করে দেখতে পারো)।
ইভালুয়েশন
মডেল তো বানাইলা, ইভালুয়েট করবা না মডেলের পার্ফরম্যান্স কেমন ? খালি কয়েকটা জেনারেটেড সেন্টেন্স দেখে কি বুঝবা । পারফরম্যান্স তো সংখ্যা দিয়ে রিপোর্ট করতে হবে। ভালো হয় নাই, মোটামুটি , চলে এসব তো আর ইভালুয়েশন মেট্রিক না!
ইভালুয়েশন ২ রকমের হয়। ইন্ট্রিন্সিক - যখন তুমি একটা টেস্ট ডেটাসেটে মডেল ইভালুয়েট করবা, আর এক্সট্রিন্সিক - যখন একেবারেই ভিন্ন কোন টাস্কে মডেল এপ্লাই করে দেখবা যে সেই টাস্কে তোমার মডেল কতটুকু হেল্প করতে পারে। যেমন, LLM গুলো বিভিন্ন QA ডেটাসেটে ইভালুয়েট করে।
$$PERPLEXITY(w_1 ... w_n) = e^{-\frac{\sum_{i = 1}^{n} ln(P(w_i))}{n}}$$
ল্যাঙ্গুয়েজ মডেলের ইন্ট্রিন্সিক ইভালুয়েশনের জন্য একটা এস্টাব্লিশড মেট্রিক হচ্ছে পারপ্লেক্সিটি। পারপ্লেক্সিটি হচ্ছে আনসার্টেইনিটি মাপার একটা মেথড। পারপ্লেক্সিটি যত কম হবে তোমার তোমার নতুন টেক্সট জেনারেট করতে তত বেশি কনফিডেন্ট বা কম আনসারটেইন হবে । আগে একটা ছোট টেস্ট ডেটাসেট বানাই, এরপর ৩ টা মডেলের পারপ্লেক্সিটি বের করবো ।
test_sentences = [
"the joker is a supervillain that embodies the ideas of anarchy and chaos",
"the joker and batman fight the battle for gotham’s soul",
"the secret identity of batman is bruce wayne an american billionaire from gotham city",
"batman is an american superhero",
"batman is a superhero",
]
from typing import List, Tuple, Dict, Any
def perplexity(probabilities: torch.Tensor, tokens: list) -> float:
norm_probabilities = probabilities.softmax(dim=-1)
perplexity_score = torch.exp(
- torch.log(norm_probabilities).mean()
).item()
return perplexity_score
# why? a progressbar looks nice!
from tqdm.auto import tqdm
def evaluate(ngram_probabilities: torch.Tensor, test_sentences: list, word_to_idx: dict):
# if 3 dims, 3-Gram .... proba matrix
N_GRAM = len(ngram_probabilities.size())
scores = torch.zeros(size=(len(test_sentences), ))
if N_GRAM == 1:
for idx, sentence in enumerate(test_sentences):
# create unigrams
unigrams = sentence.split(" ")
probas = [
# return 1 if missing
unigram_probabilities[word_to_idx.get(ug, 1)] for ug in unigrams
]
probas = torch.tensor(probas)
scores[idx] = perplexity(probas, sentence)
if N_GRAM == 2:
for idx, sentence in enumerate(test_sentences):
# create bigrams
tokens = sentence.split(" ")
bigrams = [(tokens[i], tokens[i + 1]) for i in range(len(tokens) - 1)]
probas = []
for bg in bigrams:
word1, word2 = bg
idx1, idx2 = word_to_idx[word1], word_to_idx[word2]
p = ngram_probabilities[idx1, idx2]
probas.append(p)
probas = torch.tensor(probas)
scores[idx] = perplexity(probas, sentence)
if N_GRAM == 3:
for idx, sentence in enumerate(test_sentences):
# create trigrams
tokens = sentence.split(" ")
trigrams = [(tokens[i], tokens[i+1], tokens[i+2])
for i in range(len(tokens) - 2)]
probas = []
for tg in trigrams:
word1, word2, word3 = tg
idx1, idx2, idx3 = word_to_idx.get(
word1), word_to_idx[word2], word_to_idx[word3]
p = ngram_probabilities[idx1, idx2, idx3]
probas.append(p)
probas = torch.tensor(probas)
scores[idx] = perplexity(probas, sentence)
return scores.mean(dim=-1)
avg_unigram_ppx = evaluate(unigram_probabilities, test_sentences, word_to_idx)
avg_trigram_ppx = evaluate(trigram_probabilities, test_sentences, word_to_idx)
avg_bigram_ppx = evaluate(bigram_probabilities, test_sentences, word_to_idx)
print(f"Avg Perlexity - Unigram = {avg_unigram_ppx}")
print(f"Avg Perlexity - Bigram = {avg_bigram_ppx}")
print(f"Avg Perlexity - Trigram = {avg_trigram_ppx}")
Avg Perlexity - Unigram = 9.204292297363281
Avg Perlexity - Bigram = 8.552984237670898
Avg Perlexity - Trigram = 7.294595241546631
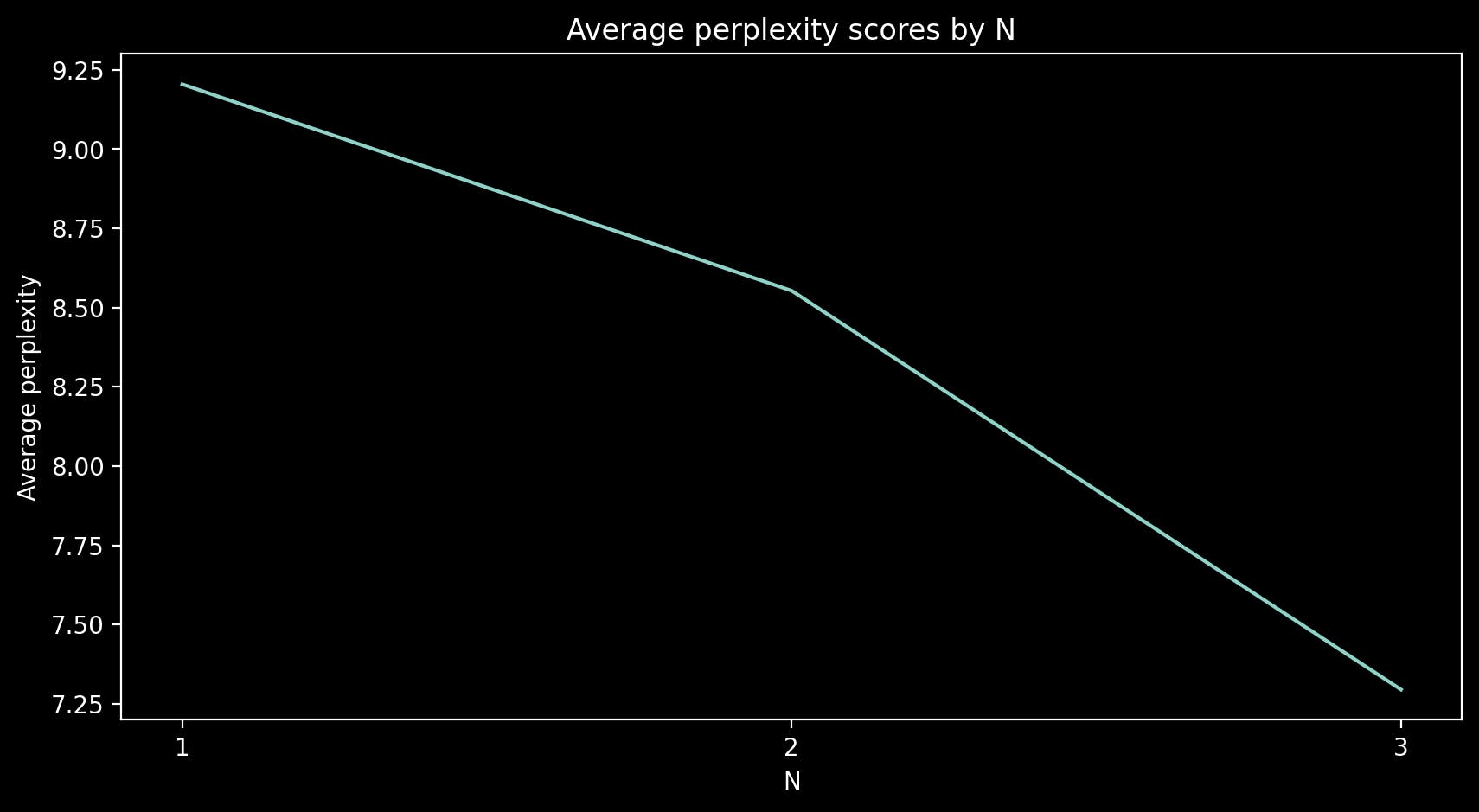
দেখতেই পাচ্ছো যে N বাড়লে পারপ্লেক্সিটিও কমে । এখন একটা ইন্টারেস্টিং জিনিস দেখাবো।
ব্যাটম্যান কে ?
আচ্ছা ল্যাঙ্গুয়েজ মডেলকে যেহেতু ভাষার জন্য ডেটাবেজ হিসাবে ধরা যায়, তাহলে এই ছোট প্যারাগ্রাফ থেকে কি আমাদের ডাম্ব মডেল ৩টার একটাও বের করতে পারবে যে ব্রুস ওয়েইনের ব্যাটম্যান হবার সম্ভাবনা বেশি নাকি জোকার ? দেখা যাক ।
sent1 = "batman is bruce wayne"
sent2 = "joker is bruce wayne"
def get_sentence_bigram_probability(sentence, bigram_probabilities, vocabulary_size=vocabulary_size):
tokens = sentence.split(" ")
bigrams = [(tokens[i], tokens[i+1]) for i in range(len(tokens) - 1)]
p = 1
for bigram in bigrams:
word1, word2 = bigram
idx1, idx2 = word_to_idx[word1], word_to_idx[word2]
p *= bigram_probabilities[idx1, idx2]
return p
def who_is_wayne(sent1, sent2, bigram_probabilities):
p1 = get_sentence_bigram_probability(sent1, bigram_probabilities)
p2 = get_sentence_bigram_probability(sent2, bigram_probabilities)
if p1 > p2:
return "Batman"
else:
return "Joker"
who_is_wayne(sent1, sent2, bigram_probabilities)
'Batman'
আরে, ঠিকই তো ধরতে পেরেছে। ওয়েইট। সেন্টেন্স দুইটা বদলে দেই, দেখো কি আসে ।
sent1 = "bruce wayne is the batman"
sent2 = "bruce wayne is the joker"
who_is_wayne(sent1, sent2, bigram_probabilities)
'Joker'
আরে অদ্ভুত! একটু আগে বললো এক কথা এখন বলে আরেক কথা! কারণ কি? কারণ হচ্ছে এখান অতিরিক্ত the শব্দটা আসায়। n-gram একটা পিওরলি ফ্রিকুয়েন্সি বেজড মডেলিং টেকনিক। এদের আর কোন ইনফরমেশন দরকার হয় না। এ কারণে এদের ইমপ্লিমেন্টেশন সিম্পল । কিন্তু শুধু ফ্রিকুয়েন্সি বের করায় এরা ভাষা থেকে কমপ্লেক্স মিনিং বের করতে পারে না। ধরো তোমার করপাসে দুইটা লাইন এমন - তিনটি হলুদ গাড়ি, পাঁচটি সাদা গাড়ি। ফ্রিকুয়েন্সি সেম হলে n-gram মডেল জীবনেও এই দুই লাইনের তফাৎ বুঝবে না। তার কাছে দুইটাই সেম। এই সমস্যার সমাধান করতে আমাদের কমপ্লেক্স নিউরাল নেটওয়ার্ক লাগে। আরেকটু মজা দেখাই। সেম সেন্টেন্স দুইটা যদি ইউনিগ্রাম প্রোবাবিলিটি দিয়ে করি তাহলে কি আসবে ?
def get_sentence_unigram_probability(sentence, unigram_probabilities, vocabulary_size=vocabulary_size):
tokens = sentence.split(" ")
p = 1
for token in tokens:
p *= unigram_probabilities[word_to_idx[token]]
return p
sent1 = "bruce wayne is the batman"
sent2 = "bruce wayne is the joker"
p1 = get_sentence_unigram_probability(sent1, unigram_probabilities)
p2 = get_sentence_unigram_probability(sent2, unigram_probabilities)
print(f"Proability of sentence 1: {p1}")
print(f"Proability of sentence 2: {p2}")
if p1 > p2:
print("Batman")
else:
print("Joker")
'Batman'
একি ভানুমতী, একি ইন্দ্রজাল!
ফাইনাল রিক্যাপ
ল্যাঙ্গুয়েজ মডেল প্রোবাবিলিটি এসাইন করে
তা দিয়ে টেক্সট জেনারেট করা যায়
ল্যাঙ্গুয়েজ মডেল ভালো হলে সেটা থেকে ইনফরমেশন ও বের করা যায়
n-gram ফ্রিকুয়েন্সি বেজড মডেল, এবং কমপ্লেক্স প্যাটার্ন ধরতে পারে না
আউট অফ ভোকাবুলারি কেস হ্যান্ডেল করতে হয়, স্মুথিং কাজে লাগে
এবং, করপাস খুব সাদামাটা হওয়াতে যে ঝামেলা পাই নাই - টোকেনাইজেশন। এখানে তো আস্ত ওয়ার্ড টোকেন হিসেবে নিয়েছি। খুব বেশি পাংচুয়েশন মার্ক ও ছিলো না ঝামেলা করতে। রিয়াল লাইফ করপাসে কি করবা ? এখনকার মডেলে কেউই আস্ত শব্দকে টোকেন হিসাবে ইউস করে না । সবাই সাবওয়ার্ড টোকেনাইজার ইউস করে। এতে করে আউট অফ ভোকাবুলারি কেস ও হ্যান্ডেল করা লাগে না, পাংচুয়েশন এবং নানাবিধ সিম্বল বাদ দেয়ার ঝামেলাও থাকে না । সাবওয়ার্ড টোকেনাইজেশন নিয়ে আমি পড়ে লিখবো নে। আপাতত এই গরু রচনা পড়ার পড় রিকোভার করতে পারলে জানাইয়ো।
Auf wiedersehen!